MCP is Dead; Long Live MCP!
Summary
- There is currently a social media and industry zeitgeist dialed-in on CLIs…just as there was a moment for MCP but just a few short months ago
- While it is true that there are token savings to be had by using a CLI, many folks have not considered how agents using custom CLIs run into the same context problem as MCP, except now without structure and many other sacrifices
- In much of the discourse, there is a lack of distinction between local MCP over
stdioversus server MCP over HTTP; the latter is a very different use case - Many folks are also only familiar with MCP tools, but overlook MCP prompts and resources as an important org- and enterprise-level mechanism for moving from cowboy vibe-coding to organizationally aligned agentic engineering.
- The importance of MCP auth is also commonly misunderstood as is the role and importance of telemetry in understanding org-wide tool use
- The oversight made by many is that individual usage of coding agents looks very different from organizational adoption of coding agents where there is an emphasis on visibility, telemetry, security, quality, and being able to operationalize and maintain agent-coded systems by a team of varying degrees of skill and experience.
- For enterprise and org-level use cases, MCP is the present and future and teams need to be able to cut through the hype of the moment.
The Influencer Driven Hype Cycle
Just 6 months back, Model Context Protocol (MCP) was all that anyone could talk about and it seemed that everyone was in a frenzy to ship MCP-related offerings and tools. At Motion, where I work, we were in the thick of it with seemingly every single vendor trying to get us to buy or use their MCP product.
It’s just an API; why do I need a wrapper around that when I can just call the API directly.
This was my common response to these vendors as they tried to pitch usage of their MCP offerings (often at a premium!). My guard was up as I looked on from the sidelines at the hype surrounding MCP with skepticism; we entirely skipped the MCP hype cycle because it wasn’t clear what the added value was.
But in just 6 short months, it seems as if the industry discourse around MCP has completely shifted. What happened?
First, most folks realized that in most use cases, MCP is just overhead to calling APIs directly because MCP as a wrapper for APIs do not make sense. Instead of using MCP, we simply wrote small tool wrappers around REST API endpoints.
Second, it is instructive to step back and understand just how much of this field is now driven by individuals marketing their companies and marketing themselves. So much of the AI landscape requires creating a sense of FOMO and hype and has been that way for years (while those of us adopting and adapting these tools on a daily basis often look on scratching our heads). These influencers constantly need some content to rant about to stay relevant and push themselves, their products, their companies, or their services so we see constant re-orientation around the zeitgeist of the moment.
In that sense, I view many of these influencers (and even people that should know better like Garry Tan and Andrew Ng) as no different than influencers peddling Ivermectin as a cure-all or anti-vax conspiracies; it’s simple ignorance.
The influencer-driven discourse has now shifted towards hating on MCP and praising CLIs as the current zeitgeist. Not without reason (to be clear) because in many cases, it is true that the CLI makes much more sense as an interface for agentic tool use…except when it does not.
Understanding the Misunderstanding
Before we dive any deeper, I would like to make clear that I think MCP is indeed the wrong choice for a class of use cases, but as the title might suggest, there is a deep misunderstanding of where and how CLI tools can yield savings and the important role of Model Context Protocol in moving orgs and enterprises towards more structured engineering with AI coding agents.
There are two topics at the core of the debate of CLI vs MCP and the foundation of much of the discussion:
- Token savings and efficiency with CLIs.
- The bloat and uselessness of MCP and its complexity.
Do Token Savings Exist?
Yes, they do. There are three modalities in token savings to be had, but it might not be as dramatic as social media would have you believe.
CLI Tools in the Training Dataset
First is that CLI utilities in the models’ training dataset like jq, curl, git, grep, psql, aws, s3, gcloud, etc. benefit tremendously from the underlying models already having encountered innumerable examples of how to use these tools. Because of this, the agent does not need additional instruction, schemas (not true when calling custom REST APIs, though), or context on how to use these tools; it can simply one-shot the tool in many cases. This can be a significant savings over MCP because in MCP, the tools must be declared up front in the tools/list response.
For CLI tools that will already be in the agent’s training dataset, absolutely always prefer them over MCP (for custom REST APIs, that’s a “maybe”).
However, this is not true of a custom, bespoke CLI tool. The LLM has no way of knowing which CLI to use and how it should use it…unless each tool is listed with a description somewhere either in AGENTS|CLAUDE.md or a README.md. You must provide the LLM some instruction on how and when to use a bespoke CLI tool that it has never seen before.
It is possible to point it to a directory called /cli-tools and rely on descriptive naming to have the agent pick and choose the tool, but anyone that works with agents day in and day out already knows that agents are often not very good at this without more explicit instructions. It will make mistakes and you will have to update your AGENTS|CLAUDE.md or other docs somewhere and fill it with more and more descriptions each time you find the agent misbehaving with your bespoke CLI tools.
Aside from that, even with a tool like curl, any token savings are lost the moment the agent has to understand a bespoke OpenAPI schema to correctly call the API since the entire OpenAPI schema may need to be loaded into context or extensive examples given to the agent in context to instruct it on how to use it. Oops; there goes all of your hyped up context savings.
Chained Extraction and Transform
In some workflows, it is possible to use a chain of CLIs to perform retrieval and then a transform or use extraction to reduce the data that makes it into the context window. In this scenario, there can be significant savings to be had, but it is also not unique to CLIs since most content that follows a format (HTML, JSON, XML, etc.) can be extracted using standard libraries via selectors (DOM/CSS, JSONPath, XPath, etc.). I don’t see this as a unique capability of a CLI based approach, but rather an underutilized approach because it is generally easier to just stuff it into context and let the LLM figure it out and optimize later.
Progressive Context Consumption
It is true that CLIs allow for progressive context consumption as an agent tries to deduce usage. Whereas MCPs will state the toolset and schema up front (the “bloat”), CLI tools can progressively load their --help into context.
// Sample from the Model Context Protocol site
{
name: "searchFlights",
description: "Search for available flights",
inputSchema: {
type: "object",
properties: {
origin: { type: "string", description: "Departure city" },
destination: { type: "string", description: "Arrival city" },
date: { type: "string", format: "date", description: "Travel date" }
},
required: ["origin", "destination", "date"]
}
}But nonetheless, the reality is that unless it is a well known tool in the LLM’s training dataset, the agent will need to progressively (and over multiple turns) descend the CLI tools’ help content to understand the available commands, sub-commands, and parameters.
There is simply no getting around this because the agent has no way of knowing how to use a bespoke CLI tool otherwise.
# What it might look like as --help output
command: searchFlights Search for available flights
input: JSON object with origin, destination, date
example:
{
origin: "(string; required) departure city",
destination: "(string; required) arrival city",
date: "(date:yyyy-MM-dd; required) travel date"
}I don’t know about you, but this sure looks like the MCP schema…just without any structure.
It is true that this could be progressively loaded instead by first listing all of the commands and then having the agent only --help the desired command to disclose the costly payload descriptor for the tool:
# Progressively loading instead of loading the entire schema
For usage:
flights <command> [--help]
commands: searchFlights Search for available flights
bookFlight Book a flight
...However, I would make 5 points here:
- For a sufficiently complex flow, the agent will end up traversing most of the tree, regardless.
- The likely context savings will end up pretty minimal if the MCP toolset is smartly designed in the first place; the agent just ends up taking more turns with a CLI while progressively discovering commands and parameter descriptors.
- Without giving the agent the full schema up front, the chance of the agent using the toolset correctly will go down. In the same way that Vercel found agent usage of docs improved when they placed the full doc index into
AGENTS.md, our intuition should tell us that if the agent is aware of all of the tools and parameters at the outset, it will be better equipped to select the right one. - Don’t give your agent complex, useless MCP tools in the first place? CLI and MCP are not mutually exclusive. Be selective in both cases.
- With Anthropic also offering 1m context window now, is this still the defining argument to make?
If you’re still not convinced that a lot of this discourse lacks nuance and is just hype, congrats on buying into the current AI-influencer FOMO hype cycle; see you in 6 months when the influencers move on to the next revelation of the moment to stay relevant and get your eyeballs and dollars.
The Duality of MCP
When the MCP hype first started, I was as much a skeptic as anyone. Motion, at the time, was building out our “AI Employees” (like every other hype-chasing team) and building integrations.
While vendors were trying to sell us on their MCP implementations of integrations, we simply wrote tool wrappers around REST API calls and passed API keys or auth info in headers using standard Bearer tokens. The hype seemed entirely unjustified and I looked on with skepticism that MCP had any future whatsoever.
Especially in stdio mode, MCP felt excessive and useless. Indeed, in most use cases, MCP over stdio is probably not needed and adds complexity over writing a simple CLI.
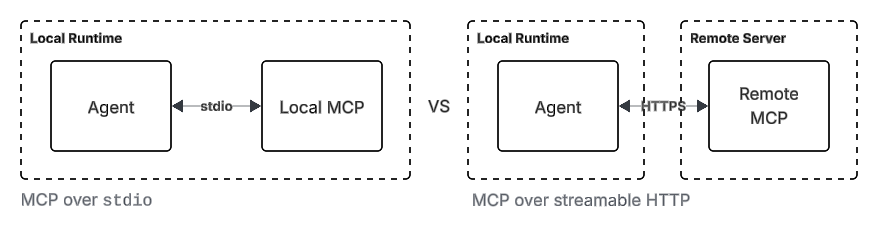
But MCP over streamable HTTP? This is an absolute game changer and will be a key linchpin in organizational and enterprise adoption shifting from vibe-coding to agentic engineering.
Why Centralization is Key
(I preface that this is primarily relevant for orgs and enterprises; it really has no relevance for individual vibe-coders)
Most influencers talking about MCP fail to make a distinction between how MCP communicates locally over stdio mode versus streamable HTTP.
In stdio mode, the MCP server runs locally with the agent and indeed, why bother with this over writing a simple CLI?
But when accessed over streamable HTTP transport, it is possible to run that same logic in a centralized server and there are several unlocks when deployed and accessed by the agents under this modality.
Richer Underlying Capabilities
What if the use case would benefit from having access to a Postgres instance? With Apache AGE enabled for Cypher graph queries over indexed context? This is very straight forward when the tooling is centralized on a server and accessed by a thin client. It is possible to implement richer platform capabilities for the tooling because distribution is as simple as pointing an agent to an HTTP endpoint and adding an auth token.
Yes, a local database like SQLite may also do the trick, but there is a limit to what’s possible and sharing state across an org becomes more difficult.
Ephemeral Agent Runtimes
Remote MCP servers over HTTP also offer big advantages depending on the runtime context.
For example, when exposing remote tools and APIs to agents running in GitHub. Here, MCP makes it trivially easy to use tools that could require complex backends without any install and without restrictions of operating in the ephemeral nature of the GitHub Actions runtime environment.

It offloads management of stateful workloads in stateless, ephemeral contexts to a centralized server.
Auth and Security
Moving workloads into a server also improves the story around auth and security. CLIs that need to access secured API endpoints using curl, as an example, require that every developer have access to keys to those APIs (or proxy calls through some server). It’s easy to see why this is bad and a pain in the ass for an ops teams.
Centralizing this behind MCP allows each developer to authenticate via OAuth to the MCP server and sensitive API keys and secrets can be controlled behind the server like any other bog-standard server REST API using (more or less) bog-standard OAuth. The exposure of secrets is controlled, limited, and easy to audit.
An engineer leaves your team? Revoke their OAuth token and access to the MCP server; they never had access to other keys and secrets to start with.
Telemetry and Observability
For teams, another big win with centralized streamable MCP is the story around telemetry and observability. Which tools are having an impact? Which agent runtimes are the team using? Which tools are low value? Where and how are tools failing? Without centralized, standardized telemetry, it is exceedingly difficult as an engineering org to understand what’s working and what’s not.
With a centralized MCP server, this is simply a matter of emitting OpenTelemetry traces and metrics and collecting them using standard, off-the-shelf tooling.
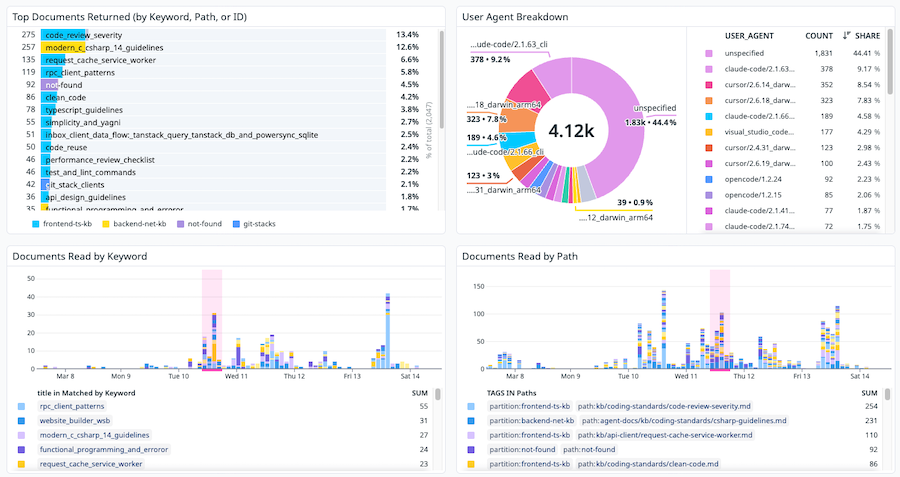
While this is achievable with CLI tools, it is far easier to do so when deploying a single server because local delivery requires consumers to update and a lot of the scaffolding that happens centrally now has to be reproduced on each CLI tool that is shipped by a team.
Standardized, Instant Delivery of Up-To-Date Content
Distributed tooling (e.g. via packages) has much the same problem as working with distributed apps: keeping deployments up to date with the latest release and API compatibility. While it is relatively straightforward to update a server to add new capabilities, if tool capabilities are delivered as local CLI tools that interact with those APIs, now API version compatibility becomes a concern.
MCP includes provisions for this: subscriptions and notifications which allow servers to call back to the client notifying them of updates.
While most folks are aware of MCP tools, relatively fewer are aware of MCP prompts and MCP resources.

Look carefully and you can see:
- MCP Prompts are effectively server-delivered
SKILL.md - MCP Resources are effectively server-delivered
/docs
Why would an org, team, or enterprise want this?
Well, it’s easy to see several benefits.
- Dynamic content. While
*.mdfiles in a repo are static text files that need to be manually updated, synced, and maintained, server produced prompts and resources have no such restrictions. It is possible to dynamically generate the text on the fly to construct a skill. What about docs? What if some docs are useful in some contexts, but not others? What if docs could benefit from dynamic injection of content/context without a tool call (pricing data, current system status, etc.)? - Automatic and consistent updates. When
*.mdfiles are delivered as part of the repo or as part of a package import, the downside is that they can become out of sync and require explicit syncs on the local system. This is not the case with server-delivered skills and resources via MCP prompts as these are always up to date. What about third party, official sources of docs and skills? Do you manually reproduce and update these in your repo? Or would it be easier to simply proxy it through a server? - Org-wide knowledge. Some content applies org-wide. For example, standard best practices for security or telemetry in apps or infrastructure deployment considerations for apps. What about orgs that use microservices where one team may need to have docs for another service. Or what if a service team could provide skills for their service dynamically each time they ship? Does it make sense to reproduce these docs into every repo? How does an org keep them up-to-date and in sync?
MCP is the answer to all of these.
If you want to deliver standard planning prompts (skills) and standard docs across all repositories, all workflows, all teams, and all agent front-ends (Claude Code, Codex, VS Code Copilot, GitHub Agents, OpenCode, etc.) consistently and always up-to-date with server telemetry to measure adherence and usage across an org, then MCP prompts and resources IS that delivery mechanism.
Here is an MCP delivered prompt in OpenCode:
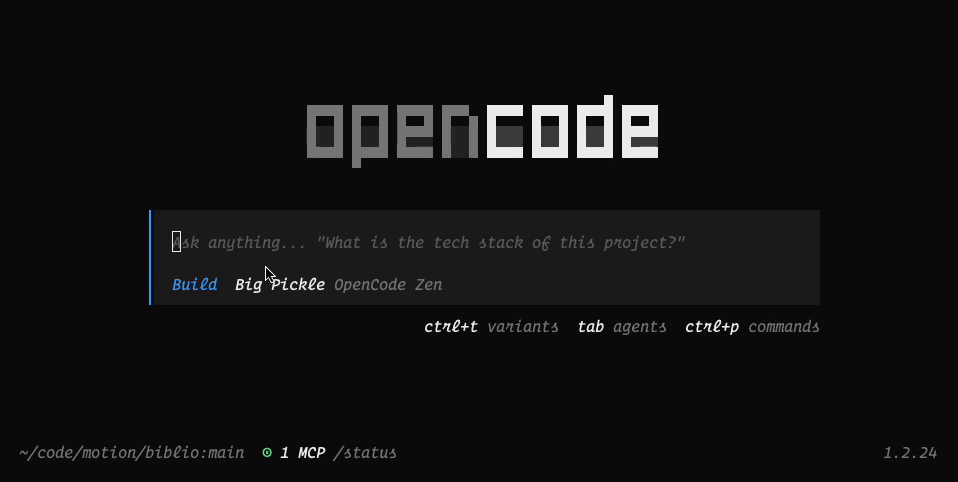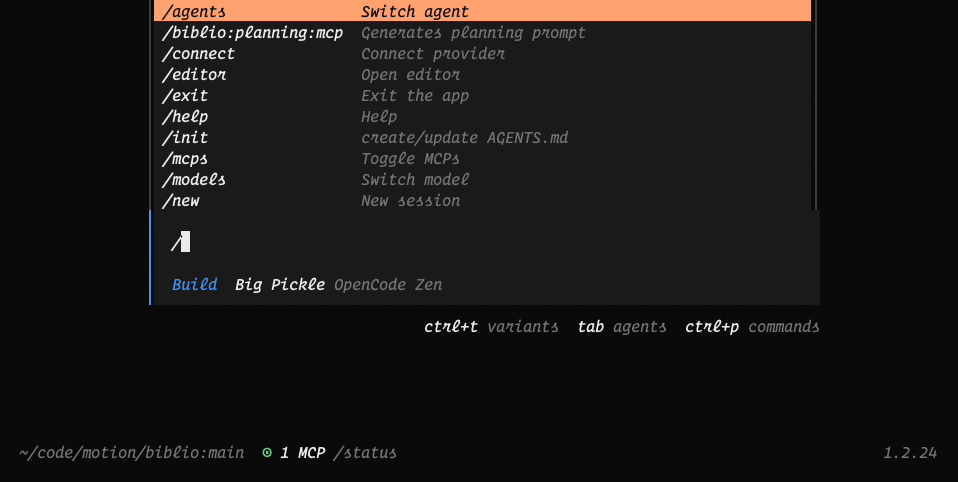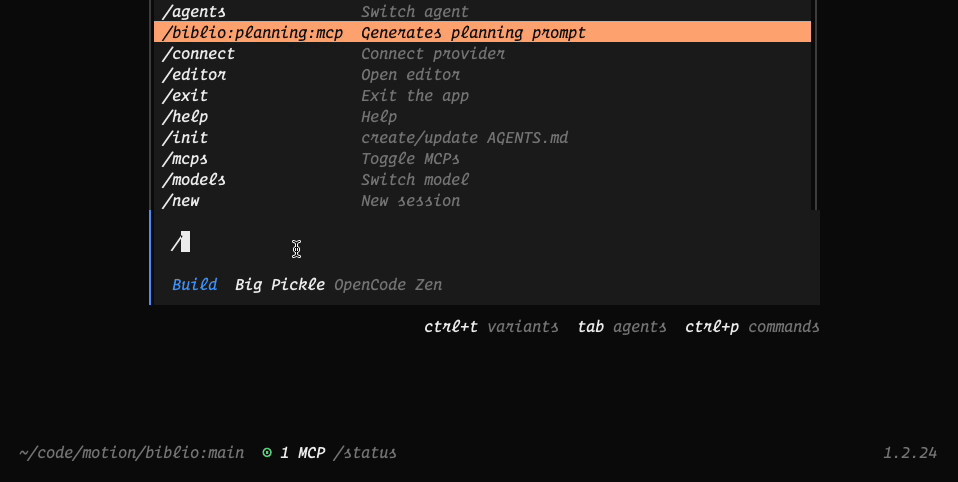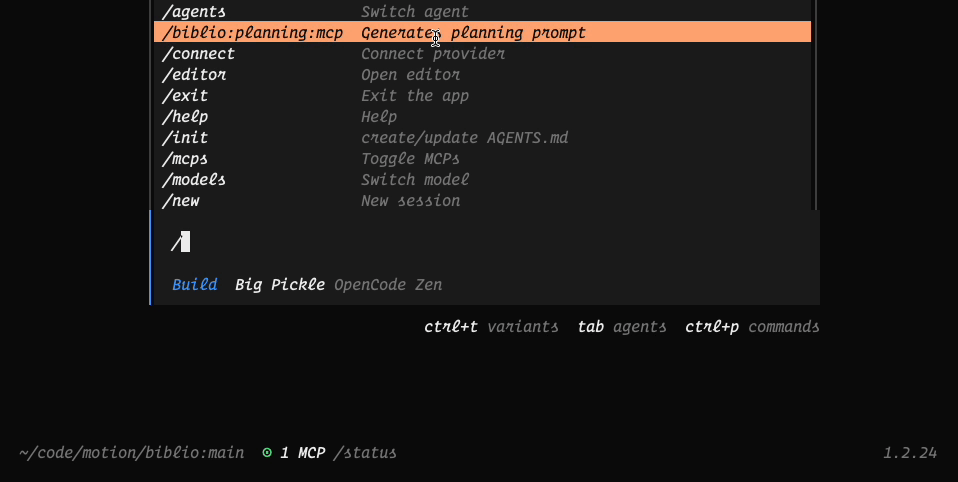
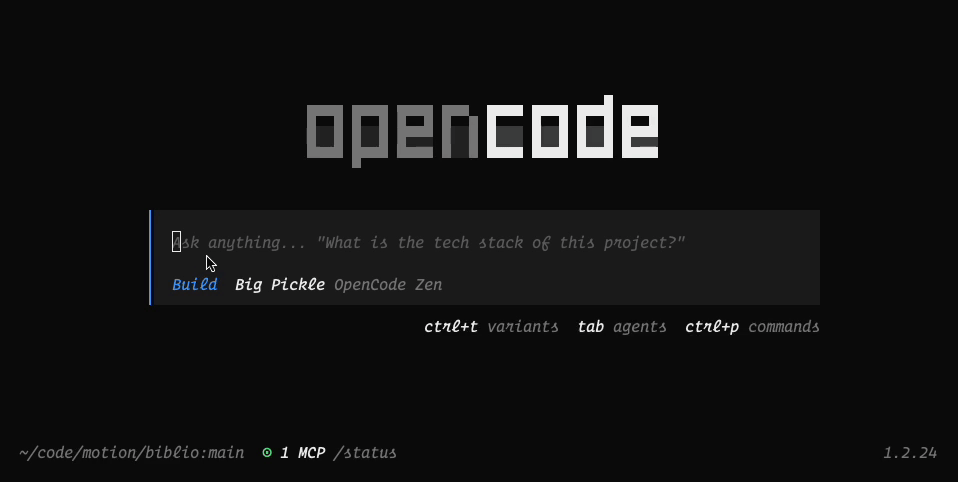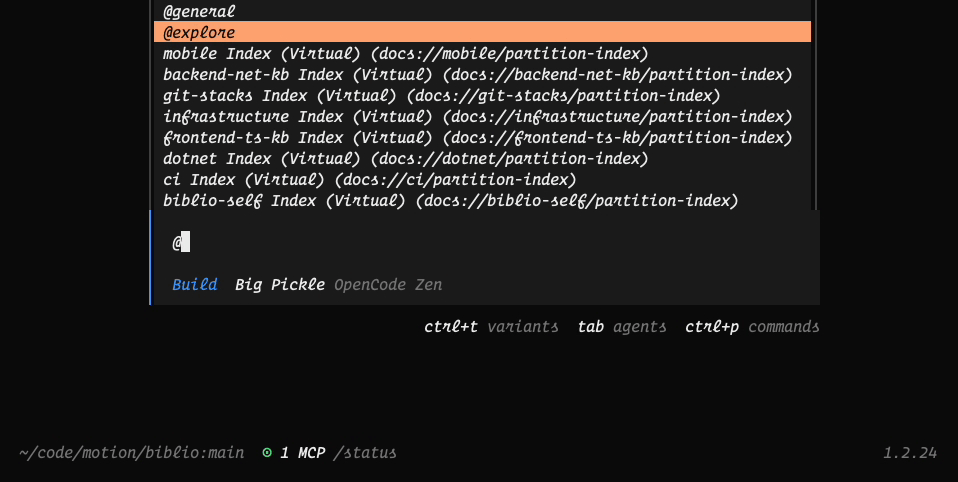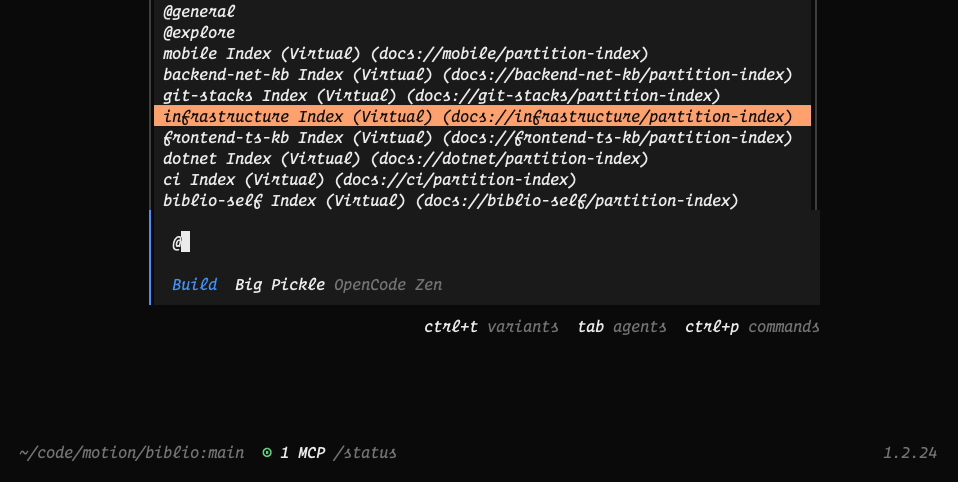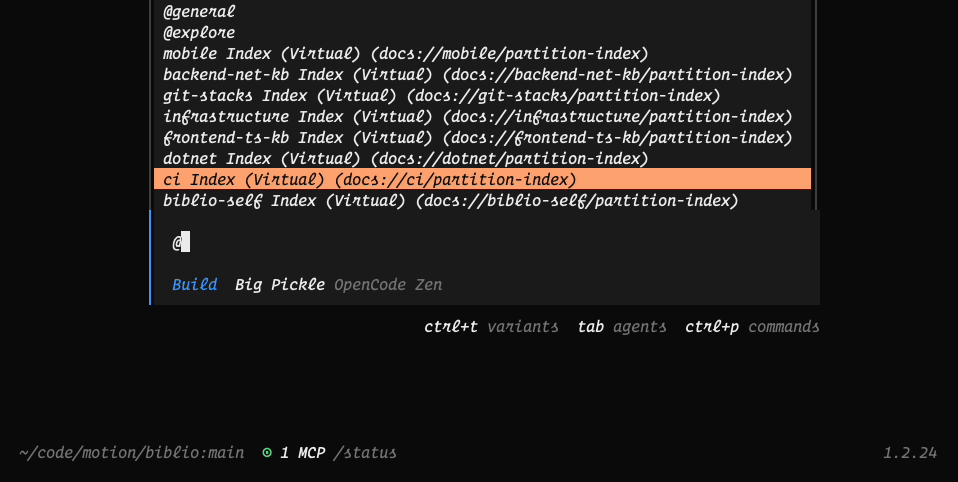
And a set of MCP delivered resources:
The same in Claude Code CLI:
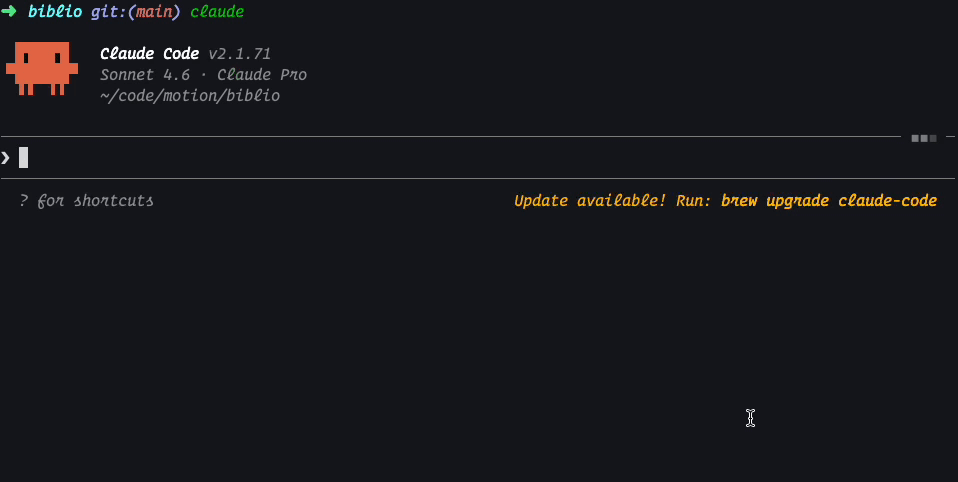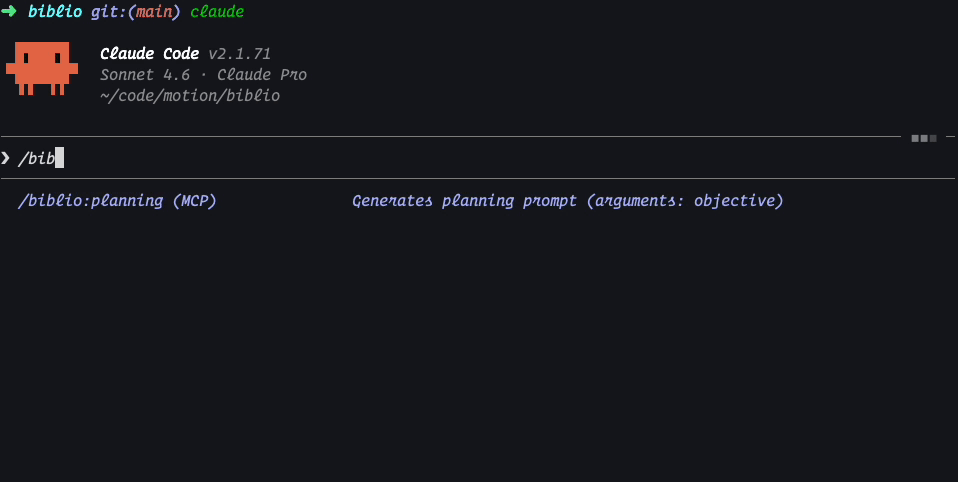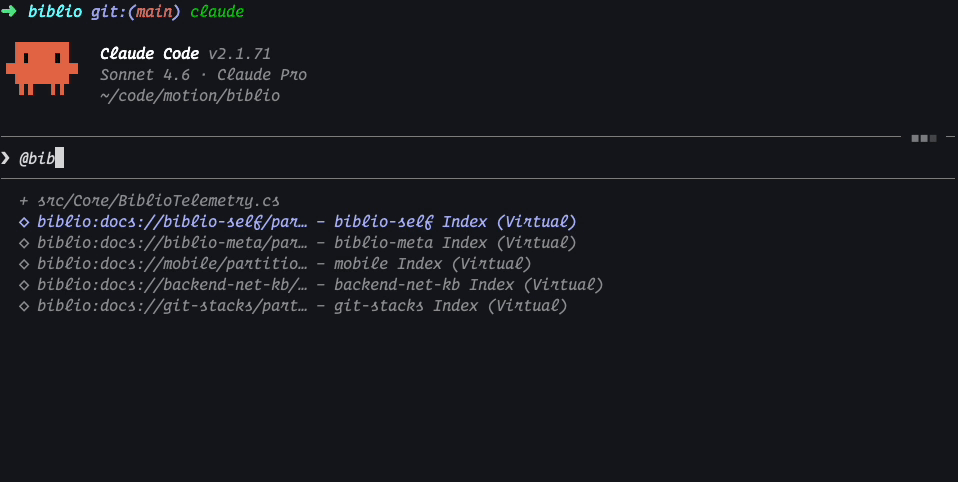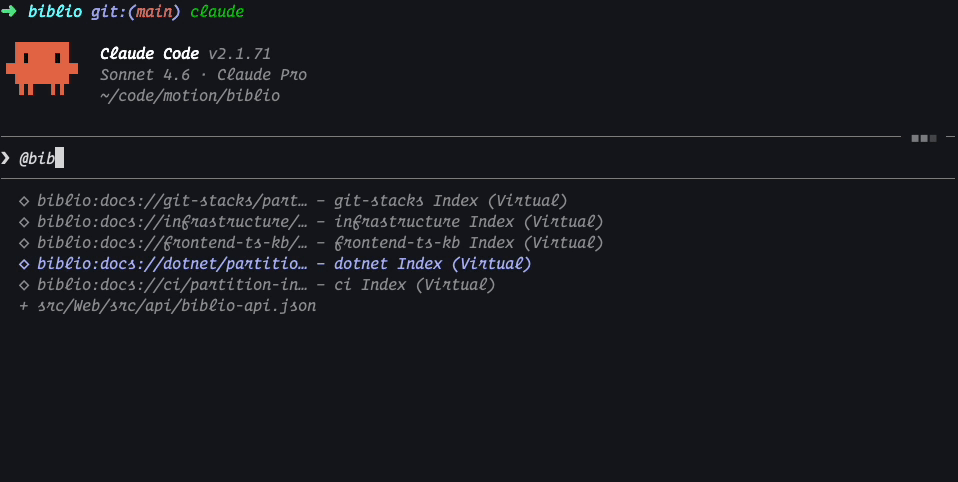
Each of these resources is a dynamically generated, “virtual” index of documents that are available (similar to Vercel’s index in AGENTS.md) and we have the benefit of bringing these documents into any project, always up-to-date, and with full server telemetry on which documents are being accessed.
In all cases, delivery of this capability requires only configuring the MCP client; it’s fire and forget with no need to keep things updated on the client.
Closing Thoughts
I get it; the industry moves fast now and these social media influencers need to keep chasing something new to keep their audience engaged. 6 months ago, MCP was the hot ticket. Now it’s a has-been; blamed for context bloat while often not even considering the tradeoffs and similar traps with custom CLIs. The masses following along have seemingly lost all critical thought in so far as engineering discipline goes.
But a simple thought exercise of how teams can move engineering orgs from vibe-coding towards agentic engineering would land one pretty squarely on the design and mission of the Model Context Protocol. In any scenario beyond a solo vibe-coder, MCP’s telemetry, simplified considerations for managing security, automatic content synchronization, schema + standards based approach, and ease of observability (how can you tell which tools are effective otherwise?) mean that teams that buy into the current zeitgeist will make a mistake when selecting an approach for delivering the scaffolding that enables agentic engineering.
We are still relatively in the early days of AI agents taking a leading role in software engineering, and because the field moves quickly, there is an emphasis on speed at all costs. But as we’ve seen with Amazon’s recent challenges in their AWS division, teams eventually have to operationalize and maintain these software systems produced by AI agents.
Take advice and anecdotes on agents from the likes of Garry Tan and Andrew Ng with a grain of salt: what works for them individually in a homogeneous environment likely will not hold true for teams and orgs in a heterogeneous environment where the objective is to ensure a team of diverse skill and experience levels converges upwards in their output and production of software.
If the goal is to ship software that is dependable and maintainable once operationalized, we still need an engineering discipline that ensures consistency, security, high quality, and correctness — even when the producer of that software is an AI agent. Organizations need architectures and processes that start to move beyond cowboy, vibe-coding culture to organizationally aligned agentic engineering practices. And for that, MCP is currently the right tool for orgs and enterprises.
Long live MCP!
All content was human written; see the file history in the repo.
